How it works
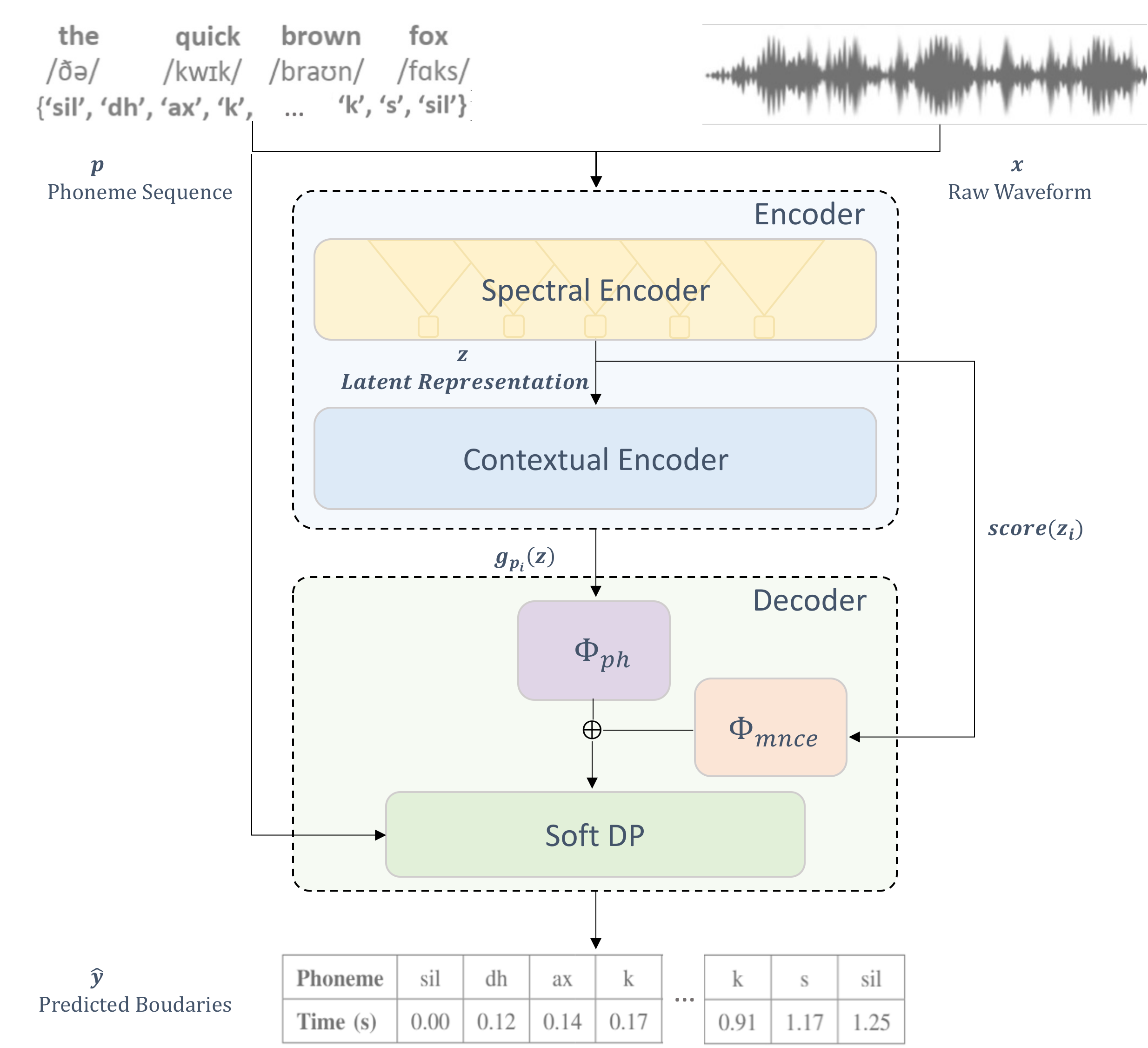
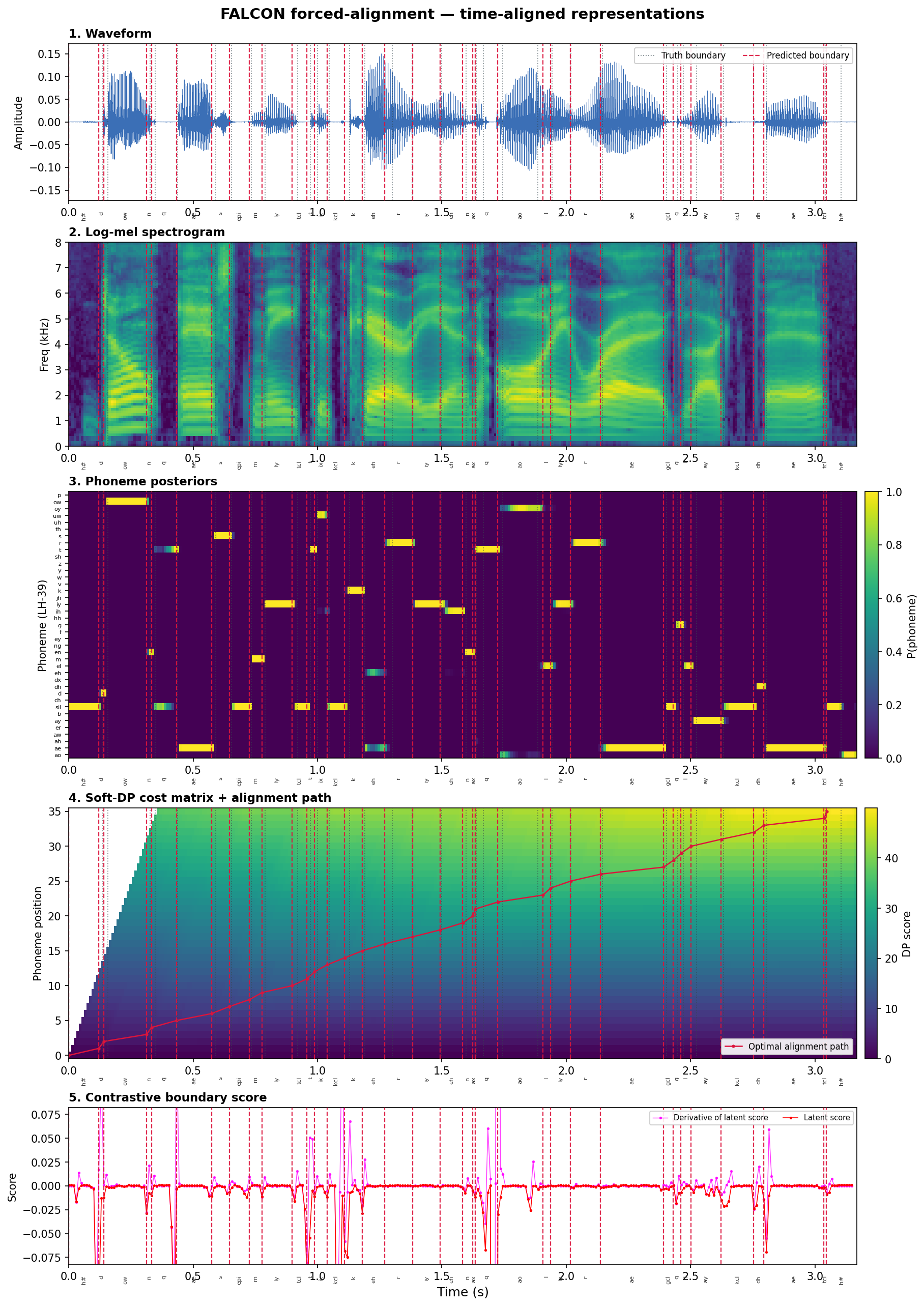
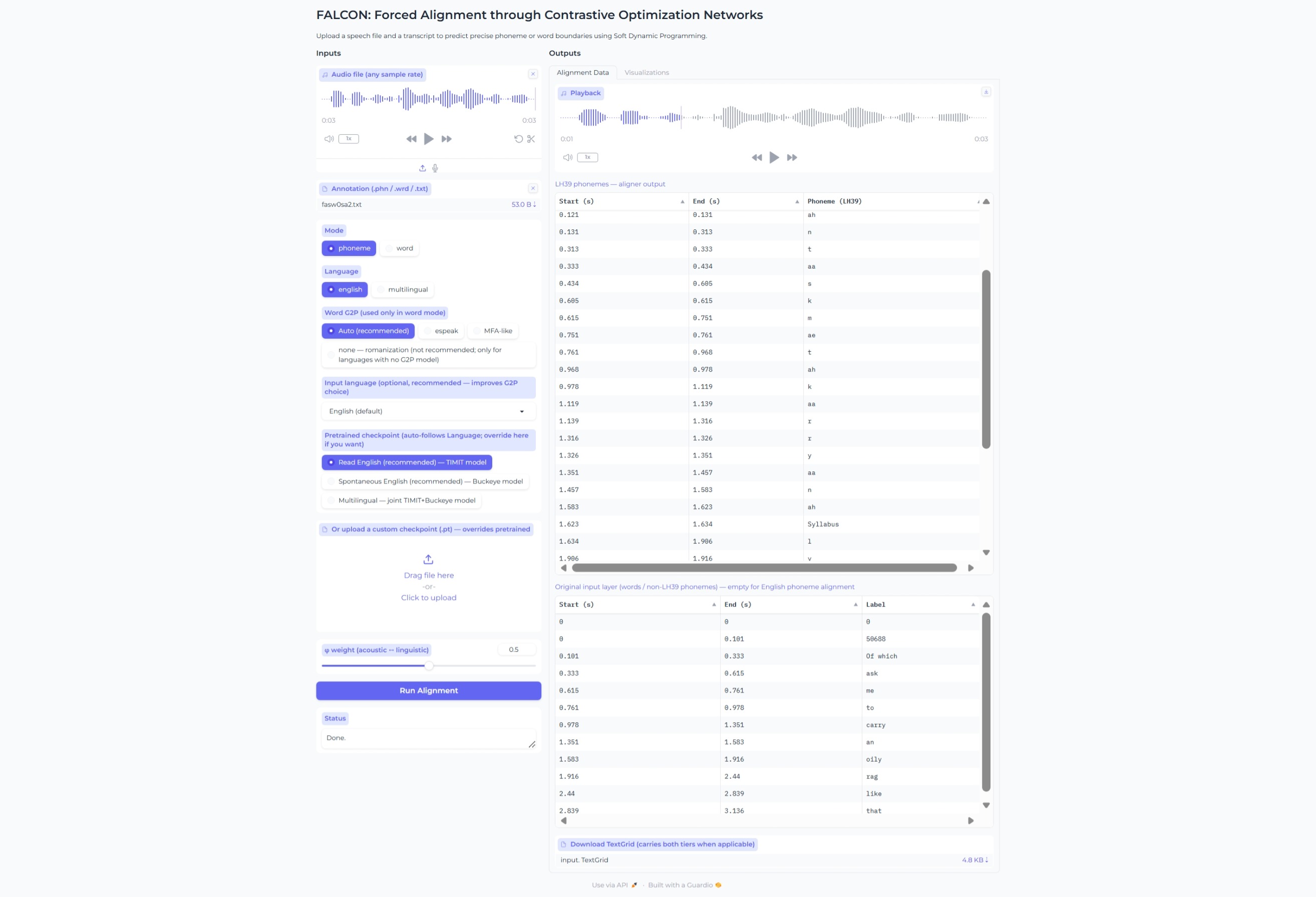
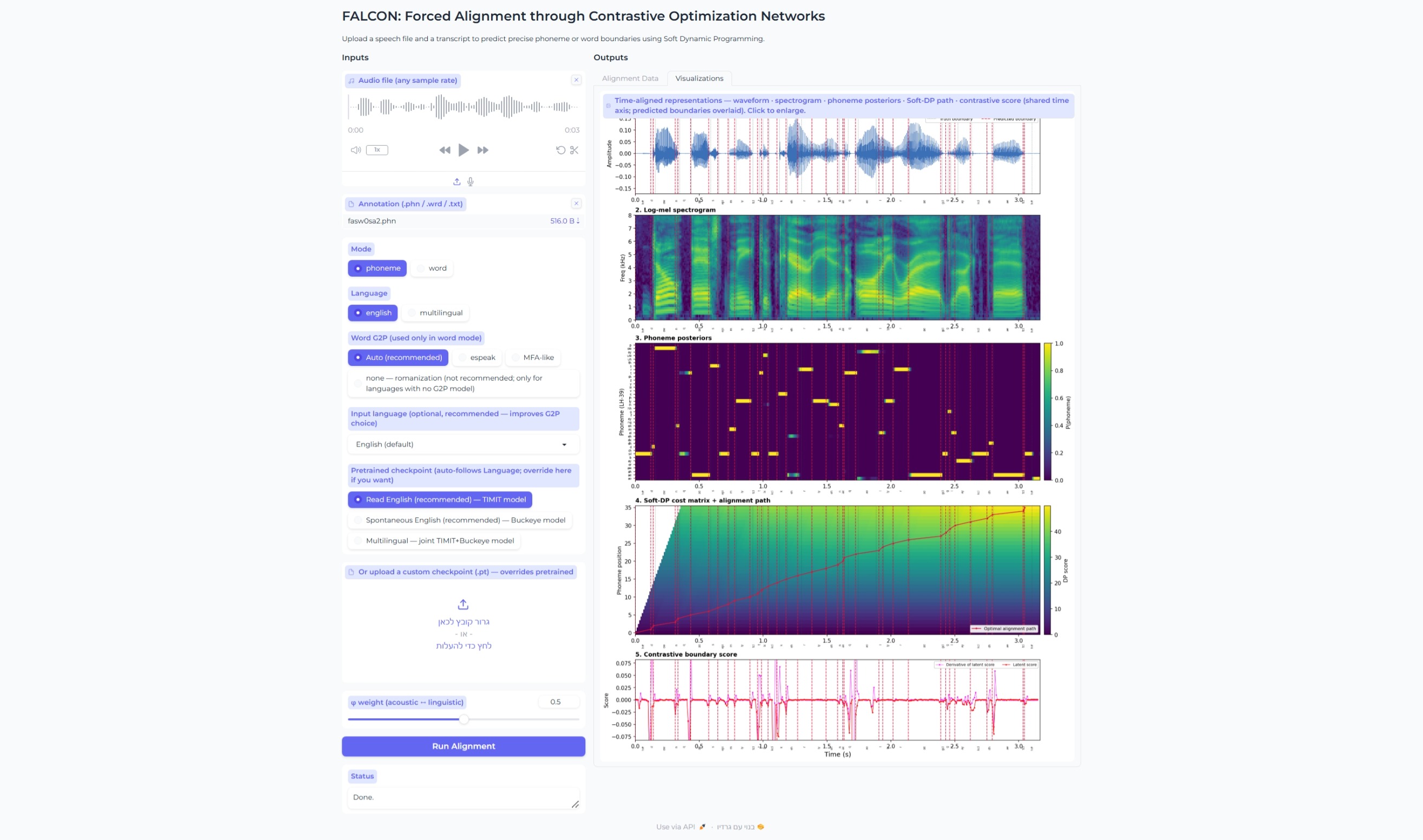
A spectral encoder and a contextual encoder turn the raw waveform into frame-level features; two branches verify phoneme identity and detect boundaries (the latter via a margin contrastive score), and a differentiable Soft-DP decoder reads both to emit the alignment. Gradients flow through the entire pipeline, so the encoder, classifier, and decoder are trained jointly.